
Introduction
The Database of Chinese Medieval Texts (DMCT) is a collaborative project between the Centre for Buddhist Studies at Ghent University (Christoph Anderl), Dharma Drum Institute of Liberal Arts (DILA, Joey Hung / Lin Ching-hui), and Marcus Bingenheimer / Zhang Bo-yong. Although it is an ongoing and open-ended project, we have decided to make a BETA-version public with a focus on the manuscripts which have been digitized and marked-up so far. The DB also includes other analytical parts (on Late Medieval Chinese syntax and sentence analysis), however, these parts will be made public at a later date. Currently, ca. 750 LMC function words are registered and analyzed, illustrated by ca. 700 parsed example sentences. Another part of the DB on phonetic loan characters in vernacular Dunhuang texts will likewise be made public at a later date.
In addition to the texts which were directly digitized in the framework of DMCT (financed by research foundations of Flanders, Ghent University, DILA / Chung-hwa Institute of Buddhist Studies, and the Tianzhu Foundation; main encoder: Lin Ching-hui [JH] 林靜慧), Marcus Bingenheimer also contributed the results from his project “Four Early Chan Texts from Dunhuang” (funded by the Chung-hwa Institute of Buddhist Studies; 2014-2017; main encoder: Zhang Bo-yong [ZBY] 張伯雍). The latter project was also published in book form. [1] For an introduction to the project and the texts, see here.
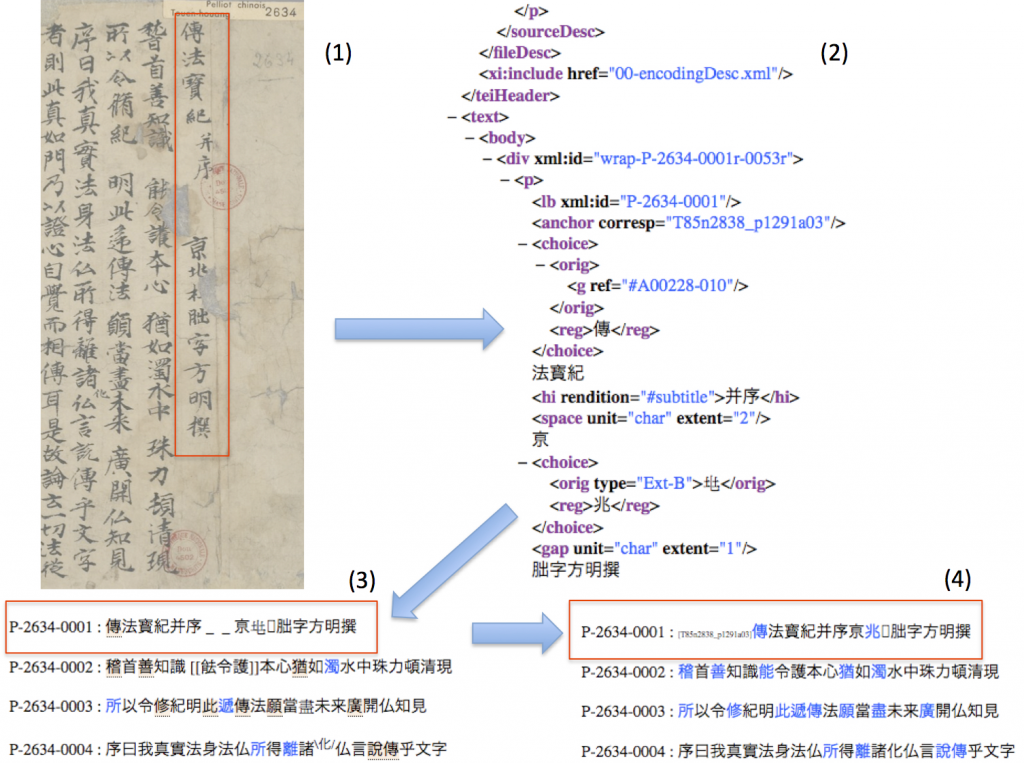
The selection of the texts digitized in the DMCT project (2015- ) has been motivated by the research interests of the participating scholars and ongoing PhD projects at GCBS. Since the initial impetus was linguistic research, many of the Dunhuang texts were selected based on their vernacular / colloquial features (syntax and semantics). As the project progressed, the focus gradually shifted to variant character forms, yitizi 異體字. As such, this Beta version will also contain a Database of Variants extracted from the digitized manuscripts. This dataset is continuously growing parallel to the digitization of new manuscripts. Most of the variant forms registered are directly linked to the manuscript line they occur in. Up to now, more than 32.000 variant character – text passage links have been collected in the Variant DB. Please be patient when entering the Variant DB. For better performance the overview of all variants will be preloaded, this process might take a few seconds.
Since the variant forms collected in the dataset are based on different projects and slightly different approaches to the mark-up, they are registered and visualized in various forms. Since the focus was not on registering every specific form, but rather on the structure of the variants, whenever possible, the images of variant forms contained in the Taiwanese DB 異體字字典, YTZZD, were used and referred to (identifiable by their number as registered in this dictionary). In the “Four Early Chan Texts from Dunhuang” project, further images of variant forms were created as part of the project (for those forms not contained in YTZZD). In the DMCT project we took these two datasets of variant forms as point of departure and used them whenever possible, however, for variants not contained in either of them, the original form as found in the respective manuscript is reproduced.
For further information on how to use the database, and technical notes, please visit here.
To register and begin using the database, please visit here.